
Story based on the “The forget-set identification problem” which is available at Journal of Machine Learning - Springer
@Article{DAngelo_Gullo_Stilo_ForSId_2025,
author = {Andrea D’Angelo and Francesco Gullo and Giovanni Stilo},
title = {The forget-set identification problem},
journal = {Machine Learning},
year = {2025},
volume = {114},
number = {11},
pages = {247},
doi = {10.1007/s10994-025-06897-9},
url = {https://doi.org/10.1007/s10994-025-06897-9},
issn = {1573-0565}
}
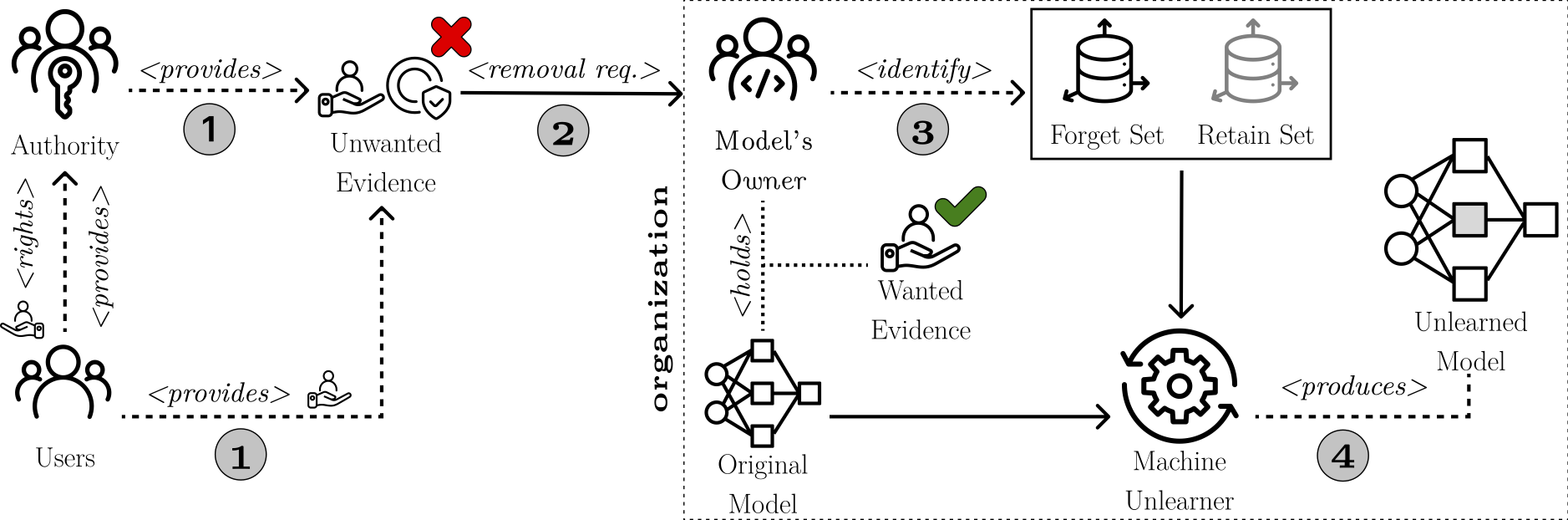
Figure 1: Overview of the overall Machine Unlearning (MU) process. Directly or indirectly (e.g., passing through some authority), users exercise their right to be forgotten (Step 1). To this end, in Step 2, they provide unwanted evidence that is required to
be unlearned through a removal request to machine-learning model’s owner. Technically, in Step 3, the organization (that is supposed to hold the wanted evidence to be maintained too) identifies the forget set, as a subset of the upstream training set, and,
optionally, a retain set. In Step 4, a MU technique is applied to the original model
so as to produce the desired one where user’s unwanted evidence has been unlearned.
So far, in the MU landscape, Steps 1–3 have been treated as a unique one, i.e., it has
been assumed that users provide their unwanted evidence directly in the form of a
forget set. This is unrealistic in many scenarios. The Forget-Set Identification
(ForSId) problem we introduce in this work is aimed at overcoming precisely such a
limitation, providing a principled way for identifying a forget set from more abstract
forms of unwanted evidence (Step 3).
Artificial intelligence systems have a remarkable talent for remembering. Every image, word, or example we feed them during training leaves an imprint in their digital memory. But what happens when we ask them to forget something?
This is not a philosophical question. In recent years, a new field called Machine Unlearning has emerged to answer precisely that: how to make machine-learning models erase the influence of specific data once it’s no longer supposed to be there. The motivations range from privacy — as in the Right to be Forgotten granted by regulations such as the European GDPR — to fairness and ethics, where we might want to remove biased or harmful content that should never have been part of the training material in the first place.
At first glance, unlearning might sound simple. Just delete the unwanted data and retrain the model. But in practice, retraining large models from scratch is often infeasible — it’s expensive, slow, and environmentally costly. Hence, researchers have been searching for smarter methods that can surgically “unlearn” without starting over. Yet there’s a deeper and subtler problem hiding underneath: before we can forget something, we need to know what exactly to forget.
The Missing Step
Most current Machine Unlearning methods assume that the user, or the organization managing the model, already knows which specific training samples should be removed — what researchers call the forget set. But this assumption rarely holds in real life. Users who ask a company to remove their personal data don’t have access to the model’s original training set. They can only describe what they want erased — for instance, by providing new examples that show the kind of information they wish the model to forget.
This gap between what users can provide and what unlearning methods require has been largely ignored in the literature. Until now.
In their 2025 paper published in Machine Learning, Andrea D’Angelo, Francesco Gullo, and Giovanni Stilo introduce a new problem that sits one step before unlearning itself: the Forget-Set Identification problem, or ForSId for short. The goal of ForSId is deceptively simple: given a trained machine-learning model, and some examples of what we don’t want it to know anymore, can we figure out which parts of the training data were responsible for teaching it that unwanted behavior in the first place?
Learning to Unlearn
The ForSId problem is like detective work for machine learning. Suppose you have a trained image classifier, and someone requests that it forget all photos containing a particular person. The user cannot provide the original training data — perhaps because it’s proprietary or anonymized — but they can submit a few images of themselves as “unwanted evidence.” The system’s job is to trace back through the model’s memory and infer which training examples most likely contributed to recognizing that person’s face. Those examples, once identified, become the forget set. Removing them (or their influence) from the model is what true unlearning requires.
The researchers define ForSId formally as an optimization problem: find the smallest subset of training samples whose removal makes the model change its predictions on the “unwanted” examples while keeping its behavior as stable as possible on “wanted” examples — the data we still care about. This balance is delicate. Make the forget set too small, and the model won’t truly unlearn. Make it too large, and the model’s useful knowledge will collapse. The art lies in finding the sweet spot where the unwanted evidence is erased but the rest of the model remains intact.
From Theory to Algorithm
Under the hood, the authors show that ForSId is NP-hard — meaning that, like many combinatorial puzzles, it cannot be solved efficiently in all cases. To navigate this difficulty, they draw a fascinating connection to a classic problem in computer science known as the Red-Blue Set Cover. In this analogy, the “blue” elements represent the unwanted evidence we want to cover and eliminate, while the “red” ones symbolize the wanted evidence we must protect.
Building on this idea, they design an algorithm called ForSId-via-RBSC, which cleverly estimates how much each training sample influences the model’s predictions and selects which ones to forget based on their impact. This approach avoids the need to retrain the model for every possible subset — something that would be computationally impossible — by using statistical influence measures as proxies.
Putting It to the Test
To test their method, the team ran extensive experiments on well-known datasets such as CIFAR-10, CIFAR-20, CIFAR-100, and the Wine Quality dataset. These datasets range from image classification to tabular prediction tasks, offering a broad view of the algorithm’s performance.
The results were striking. Across all datasets and experimental conditions, the proposed ForSId-via-RBSC consistently outperformed several baseline strategies. It achieved high unlearning efficacy (meaning it successfully erased unwanted knowledge) while preserving the model’s accuracy on data it was meant to retain. Even when the line between “wanted” and “unwanted” examples was blurred — the hardest case — ForSId proved robust and stable.
In the simplest terms, their algorithm could teach models to forget effectively, without forgetting too much.
Why This Matters
Machine learning is moving out of the lab and into every corner of society — from recommendation systems and chatbots to hiring tools and autonomous vehicles. As these systems become more pervasive, the ability to make them forget specific information responsibly becomes a cornerstone of trustworthy AI.
ForSId is an essential step in that direction. It makes unlearning practical in cases where the precise training data is unknown or inaccessible — which is to say, in most real-world situations. It also opens new possibilities for ethical and regulatory compliance, allowing AI developers to respond to deletion requests or remove biased behavior without rebuilding their models from scratch.
A Small but Vital Step Toward Conscious Machines
The contribution of D’Angelo, Gullo, and Stilo is not merely technical. It reframes what forgetting means for artificial intelligence. Forgetting, in this context, is not about erasing memory blindly but about making informed choices about what to unlearn — choices guided by evidence, ethics, and responsibility.
In human terms, that’s the difference between amnesia and deliberate reflection. In AI terms, it’s the foundation for systems that can evolve without perpetuating their past mistakes.