
Developing and Evaluating Graph Counterfactual Explanation with GRETEL
Demo at WSDM 2023: The 16th ACM International Conference on Web Search and Data Mining on Mar. 2, 2023
Organisers

Mario A. Prado-Romero

Dr. Bardh Prenkaj

Prof. Giovanni Stilo
Tutorial's Materials
Slides are available HERE
Tutorial is based on ACM Computing Survey: A Survey on Graph Counterfactual Explanations: Definitions, Methods, Evaluation, and Research Challenges
Abstract
The black-box nature and the lack of interpretability detract from constant improvements in Graph Neural Networks (GNNs) performance in social network tasks like friendship prediction and community detection. Graph Counterfactual Explanation (GCE) methods aid in understanding the prediction of GNNs by generating counterfactual examples that promote trustworthiness, debiasing, and privacy in social networks. Alas, the literature on GCE lacks standardised definitions, explainers, datasets, and evaluation metrics. To bridge the gap between the performance and interpretability of GNNs in social networks, we discuss GRETEL, a unified framework for GCE methods development and evaluation. We demonstrate how GRETEL comes with fully extensible built-in components that allow users to define ad-hoc explainer methods, generate synthetic datasets, implement custom evaluation metrics, and integrate state-of-the-art prediction models.
GRETEL Overview
To provide the readers with a reference picture of GRETEL, we review its basic concepts and architecture. GRETEL was designed keeping in mind the point of view of a user (researcher or company employee) who wants to perform an exhaustive set of evaluations. The users can easily use and extend the framework in terms of datasets, explainers, metrics, and prediction models. The framework was designed using the Object-Oriented paradigm, where the framework's core is constituted mainly by abstract classes which need to be specialised in their implementations. To promote the framework's extensibility, the authors adopted the "Factory Method" design pattern and leveraged configuration files as constituting part of the running framework. The figure below illustrates the interaction between the main components of GRETEL.
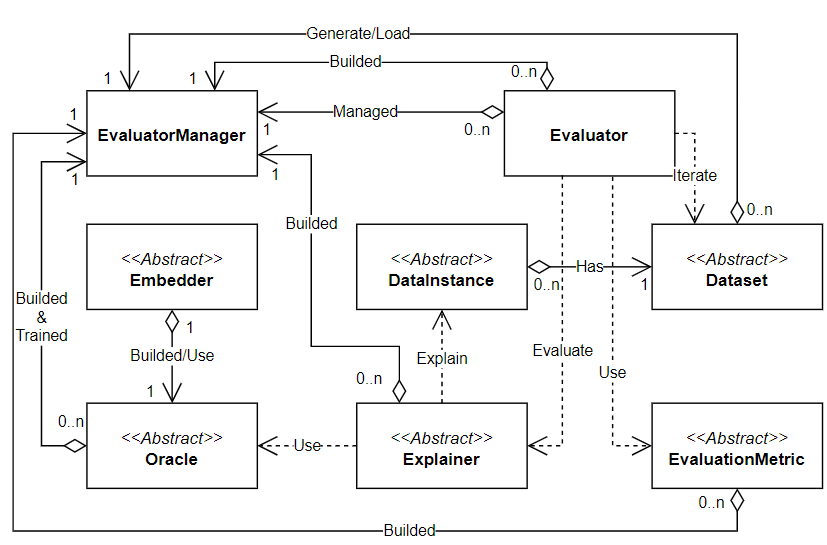
The Explainer is the base class used by all explanation methods. The Evaluator evaluates a specific Explainer. The subclasses of EvaluationMetric define specific metrics that will be used to assess the quality of the Explainer. The Oracle provides a generic interface for interacting with the underlying prediction models. The EvaluatorManager facilitates running experiments specified by the configuration files and instantiating all the components needed to perform the different evaluations. The DataInstance class provides an abstract way to interact with data instances. The Dataset class manages all the details related to generating, reading, writing, and transforming the data.
To mitigate the efforts needed to evaluate new settings, GRETEL can generate synthetic datasets and train a model on the fly if it is not already stored and readily available. A more detailed description of the framework components can be found here.
Creating a Custom Explainer
Here, we explain how to create a custom explanation method by extending the Explainer base class. Throughout this example, we assume that we use the datasets and oracles already available in GRETEL.
import Explainer
"""
Fragment 1: Minimal Code to implement a Custom Explainer
"""
class DummyExplainer(Explainer):
def __init__(self, id, config_dict=None) -> None:
super().__init__(id, config_dict)
self._name = 'DummyExplainer'
def explain(self, instance, oracle, dataset):
instance_label = oracle.predict(instance)
counterfactual = instance
for d_inst in dataset.instances:
d_inst_label = oracle.predict(d_inst)
if instance_label != d_inst_label:
counterfactual = d_inst
return counterfactual
return counterfactual
The previous code shows how to create a "dummy" explainer that searches for the first counterfactual example in the dataset. The code fragment depicts the class DummyExplainer that inherits from the Explainer abstract class. The __init__ method only assigns a name to the explainer and calls the same method from the parent class. Notice that the constructor of the explainer takes as input a configuration dictionary that contains the necessary parameters to build an explanation, including the storage path of the real/synthetic dataset.As shown, the explain method takes in input the instance to explain, the oracle to question, and the dataset to which the counterfactual explainer (might) want to access. This trivial explainer searches the dataset and returns the first instance - the counterfactual explanation - whose label differs from the one taken in the input. Notice that only one method must be implemented to create a custom explainer.
The second step, depicted by code fragment 2, explains how to create a CustomExplainerFactory that inherits from the ExplainerFactory base class. This new factory needs to access the DummyExplainer while maintaining access to other explainers already available in GRETEL. Thus, notice that CustomExplainerFactory has a new method called get_dummy_explainer() to create the DummyExplainer. Additionally, it must override the get_explainer_by_name() method of the parent class. Where checks if the explainer specified in the configuration file is an instance of DummyExplainer: in that case, the newly defined explainer is returned; otherwise, the same method in the parent class is called. Finally, it is possible to create the CustomExplainerFactory and pass it to the EvaluatorManager. The main part of the following shows how to create an EvaluatorManager, which uses the newly extended factory.
import ExplainerFactory, EvaluationMetricFactory
"""
Fragment 2: Code to implement a Custom Explainer Factory
"""
class CustomExplainerFactory(ExplainerFactory):
def __init__(self, explainer_store_path):
super().__init__(explainer_store_path)
def get_explainer_by_name(self, explainer_dict, metric_factory): -> Explainer
explainer_name = explainer_dict['name']
if explainer_name == 'dummy_explainer':
# Returning the explainer
return self.get_dummy_explainer(explainer_dict)
return super().get_explainer_by_name(explainer_dict, metric_factory)
def get_dummy_explainer(self, config_dict=None):
result = DummyExplainer(self._explainer_id_counter, config_dict)
self._explainer_id_counter += 1
return result
if __name__ == '__main__':
ex_factory = CustomExplainerFactory(ex_store_path)
evm = EvaluatorManager(config_file_path, run_number=0, explainer_factory=ex_factory)
evm.create_evaluators()
evm.evaluate()
Creating a Custom Synthetic Dataset
In this scenario, we want to use an already available explanation method (or the custom one) on an ad-hoc synthetic dataset. The new custom dataset class must inherit from Dataset. The code fragment 3 shows how to create a new synthetic dataset where each instance is a cycle graph with either three (triangle) or four (square) vertices.
import DataInstance, Dataset
import networkx as nx
import numpy as np
"""
Fragment 3: Code to implement a Custom Dataset
"""
class SquaresTrianglesDataset(Dataset):
def __init__(self, id, config_dict=None) -> None:
super().__init__(id, config_dict)
self.instances = []
def create_cycle(self, cycle_size, role_label=1):
# Creating an empty graph and adding the nodes
graph = nx.Graph()
graph.add_nodes_from(range(0, cycle_size))
# Adding the edges of the graph
for i in range(cycle_size - 1):
graph.add_edges_from([(i, i + 1)])
graph.add_edges_from([(cycle_size - 1, 0)])
# Creating the dictionary containing the node labels
node_labels = {n:role_label for n in graph.nodes}
# Creating the dictionary containing the edge labels
edge_labels = {e:role_label for e in graph.edges}
# Returning the cycle graph and the role labels
return graph, node_labels, edge_labels
def generate_squares_triangles_dataset(self, n_instances):
self._name = f'st_ninst-{n_instances}'
result = []
for i in range(0, n_instances):
is_triangle = np.random.randint(0,2)
data_instance = DataInstance(
self._instance_id_counter)
self._instance_id_counter += 1
i_name = f'g{i}'
# Create the instance shape-specific properties
cycle_size = 3 if is_triangle else 4
role_label = 1 if is_triangle else 0
# Create the triangle/square graph
i_graph, i_node_labels, i_edge_labels =
self.create_cycle(cycle_size=cycle_size, role_label=role_label)
data_instance.graph_label = role_label
# Creating the general instance properties
data_instance.graph = i_graph
data_instance.node_labels = i_node_labels
data_instance.edge_labels = i_edge_labels
data_instance.name = i_name
result.append(data_instance)
# return the set of instances
self.instances = result
The SquaresTrianglesDataset class has a very simple initialisation method that creates just an empty list of instances. The method create_cycle() builds square and triangle graphs relying on the networkx library. The generate_squares_triangles_dataset() method creates the synthetic dataset choosing at random to populate it with a square or a triangle data instance. The methods write_data() and read_data(), useful to store and load the dataset respectively, are already provided by the parent class, and, thus, they do not need to be implemented in this child one. Once the new dataset class is implemented, we need to create a CustomDatasetFactory to make it available to the framework. Fragment 4 shows how to perform this implementation.
The CustomDatasetFactory follows the same main logic as the CustomExplainerFactory. In get_dataset_by_name() method is possible to set the dataset generation parameters. Furthermore, it can be created the get_squares_triangles_dataset() method needed to generate the square and triangle dataset on the fly. The use of CustomDatasetFactory in the EvaluatorManager follows the same steps as in the previous use case.
import Dataset, DatasetFactory
import os, shutil
"""
Fragment 4: Code to implement a Custom Dataset Factory
"""
class CustomDatasetFactory(DatasetFactory):
def __init__(self, data_store_path) -> None:
self._data_store_path = data_store_path
self._dataset_id_counter = 0
def get_dataset_by_name(self, dataset_dict) -> Dataset:
dataset_name = dataset_dict['name']
params_dict = dataset_dict['parameters']
# Check if the dataset is a squares-triangles dataset
if dataset_name == 'squares-triangles':
if not 'n_inst' in params_dict:
raise ValueError('''"n_inst" parameter is required for squares-triangles dataset''')
return self.get_squares_triangles_dataset(params_dict['n_inst'], False, dataset_dict)
else:
# call the base method in to generate any of the originally
# supported datasets
return super().get_dataset_by_name(dataset_dict)
def get_squares_triangles_dataset(self, n_instances, regenerate, config_dict) -> Dataset:
result = SquaresTrianglesDataset(self._dataset_id_counter, config_dict)
self._dataset_id_counter+=1
ds_name = f'squares-triangles_instances-{n_instances}'
ds_uri = os.path.join(self._data_store_path, ds_name)
ds_exists = os.path.exists(ds_uri)
if regenerate and ds_exists:
shutil.rmtree(ds_uri)
if(ds_exists):
result.read_data(ds_uri)
else:
result.generate_squares_triangles_dataset(n_instances)
result.generate_splits()
result.write_data(self._data_store_path)
return result
Creating a Custom Metric
We illustrate how to implement a new bespoke metric that better represents the user's evaluation needs by leveraging GRETEL's components. In code fragment 5, we show how to create the Validity metric, which implements (for simplicity) the same logic as the built-in Correctness one. The straightforward implementation of the custom evaluation metric can be achieved by extending the EvaluationMetric base class and overriding the evaluate method. The process to create a custom EvaluationMetricFactory is similar to the one of the other previously explained factories. Hence, we do not provide the reader with the code fragment corresponding to CustomEvaluationMetricFactory. Note that this functionality is useful for future research since, typically, the set of used metrics tends to evolve over time while the field of research becomes more mature.
import EvaluationMetric
"""
Fragment 5: Code to implement a new evaluation metric
"""
class ValidityMetric(EvaluationMetric):
"""Verifies that the class from the counterfactual example
is different from that of the original instance"""
def __init__(self, config_dict=None) -> None:
super().__init__(config_dict)
self._name = 'Validity'
def evaluate(self, instance_1, instance_2, oracle):
label_instance_1 = oracle.predict(instance_1)
label_instance_2 = oracle.predict(instance_2)
oracle._call_counter -= 2
return int(label_instance_1 != label_instance_2)